Maximizing Insights While Streamlining Storage
Pulsedive's approach to data storage with "Properties" enables richer insights, powerful querying, and faster onboarding of new enrichment sources.

Pulsedive's approach to data storage with "Properties" enables richer insights, powerful querying, and faster onboarding of new enrichment sources.
Background
Pulsedive currently collects several types of data from different sources, including:
- HTTP headers, SSL certificate metadata, cookies, and meta tags from headless browser scanning
- Location and domain registration information from WHOIS lookups and GeoIP databases
- DNS and reverse DNS records for domains and IPs
Moving forward, more data will be collected and parsed in new and exciting ways for more valuable insights.
Naturally, Pulsedive needs a way to store all of this data to meet the use cases of analysts. Many solutions choose to store each type of data in separate database tables, but when anticipating new data sources, this can require more time for updating code, since APIs and other services will need to be updated to query the new data. They might also choose to store the full raw data, providing analysts with full context into the domain or IP they're investigating.
Pulsedive takes a different approach, with many advantages.
Properties and How They're Stored
Pulsedive stores much of the data it collects as key-value pairs, called "properties," and assigns a property "type" to each pair, so technically properties are 3-tuples. Pulsedive's ingestion engine parses the data collected into property "names" and property "values."
For example, Pulsedive stores DNS data like so:
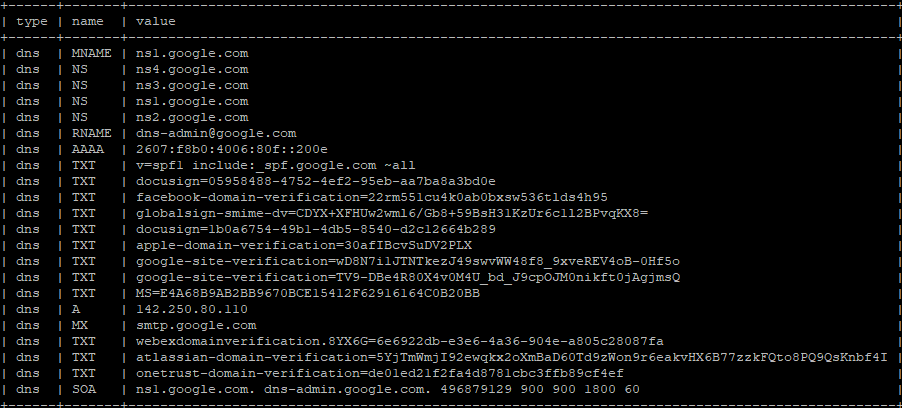
HTTP headers, meta tags, and other data types are parsed and stored in the same way.
Each time a request is made, new properties are added to the database and linked to an indicator (IP, URL, or domain). If a new request includes properties that match existing ones, the timestamps for the existing properties will be updated. This allows Pulsedive to track unique properties and avoid storing a ton of duplicate data that offers little to no valuable insight.
This type of schema is nothing new in the world of databases. It's known as the Entity-Attribute-Value (EAV) model, and it's ideal for Pulsedive's use case.
Advantages
This approach has several advantages for analysts investigating indicators, developers integrating our data, and even Enterprise TIP customers.
More Precise Querying
Because properties are divided into key-value pairs, queries can be run on property types, names, and values. Individual values can also be queried for several property types, enabling searches across all types of enrichment data at once.
property=*@google.com will query the value *@google.com across meta, whois, dns, and all other property types in Pulsedive.Combined with Boolean logic and wildcards, there are endless possibilities for querying the data that Pulsedive collects. You can query indicator properties yourself right now for free using our Explore query language, no account needed.
Higher Quality Insights
Since Pulsedive is not storing large chunks of text such as raw WHOIS responses, we can easily show changes in historical data and garner insights on individual properties. This is reflected in the Properties section on Pulsedive's indicator pages:
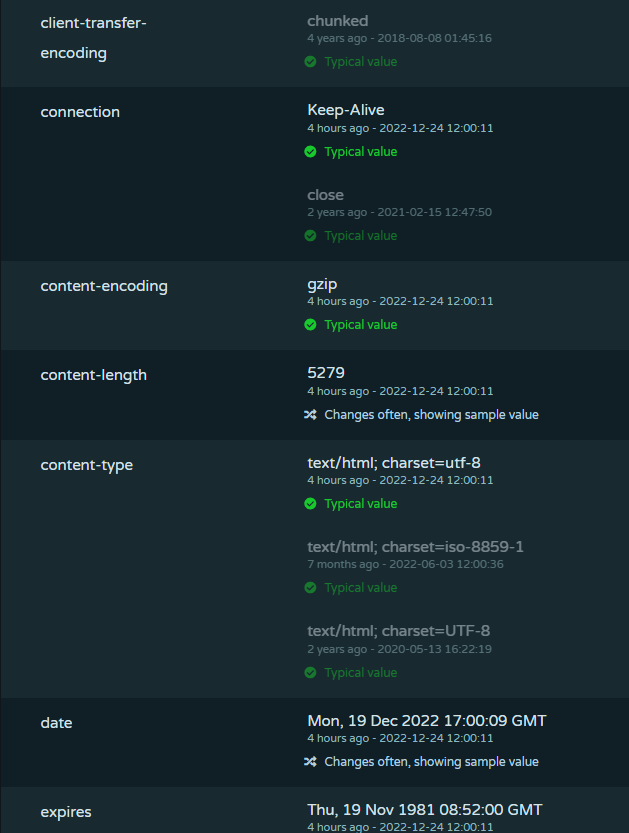
Pulsedive can determine which properties typically appear, which properties are seen with many high-risk indicators, and which ones are known to change with each request and are thus not particularly useful.
Streamlined Risk Scoring
Risk scoring is a tricky business. It becomes trickier when risk algorithms are improved and iterated upon because the entire indicator dataset must be updated to reflect new determinations.

Pulsedive's risk scoring is easier to manage because indicator properties are used to help evaluate risk. We can check for specific property names or values to make determinations, so risk scoring can be quickly done on the fly when users run an on-demand passive or active scan with Pulsedive.
Efficient Storage
The aforementioned EAV model allows us to store data efficiently because we are only storing unique data. Since we are not storing the raw text of responses from data collection and are removing duplicate data, we can keep our computing resources low. This helps us remain lean as a startup, and allows us to keep our community platform free and prices reasonable across our products. Additionally, customers seeking an on-premise TIP won't need significant resources to run a value-generating Pulsedive Enterprise instance in their environment.
Faster Fetching
Other solutions might store WHOIS data, HTTP headers, or other data types in separate tables. This means that to fetch data for an indicator, they would have to query several tables. Pulsedive just needs to query a single table, fetching data quickly with fewer queries.
While larger industry competitors might have more expansive infrastructures and computing resources for faster fetch times, Pulsedive benefits from comparable fetch times with a smaller footprint. This is reflected in our API response times; you can test out live requests in our API docs.
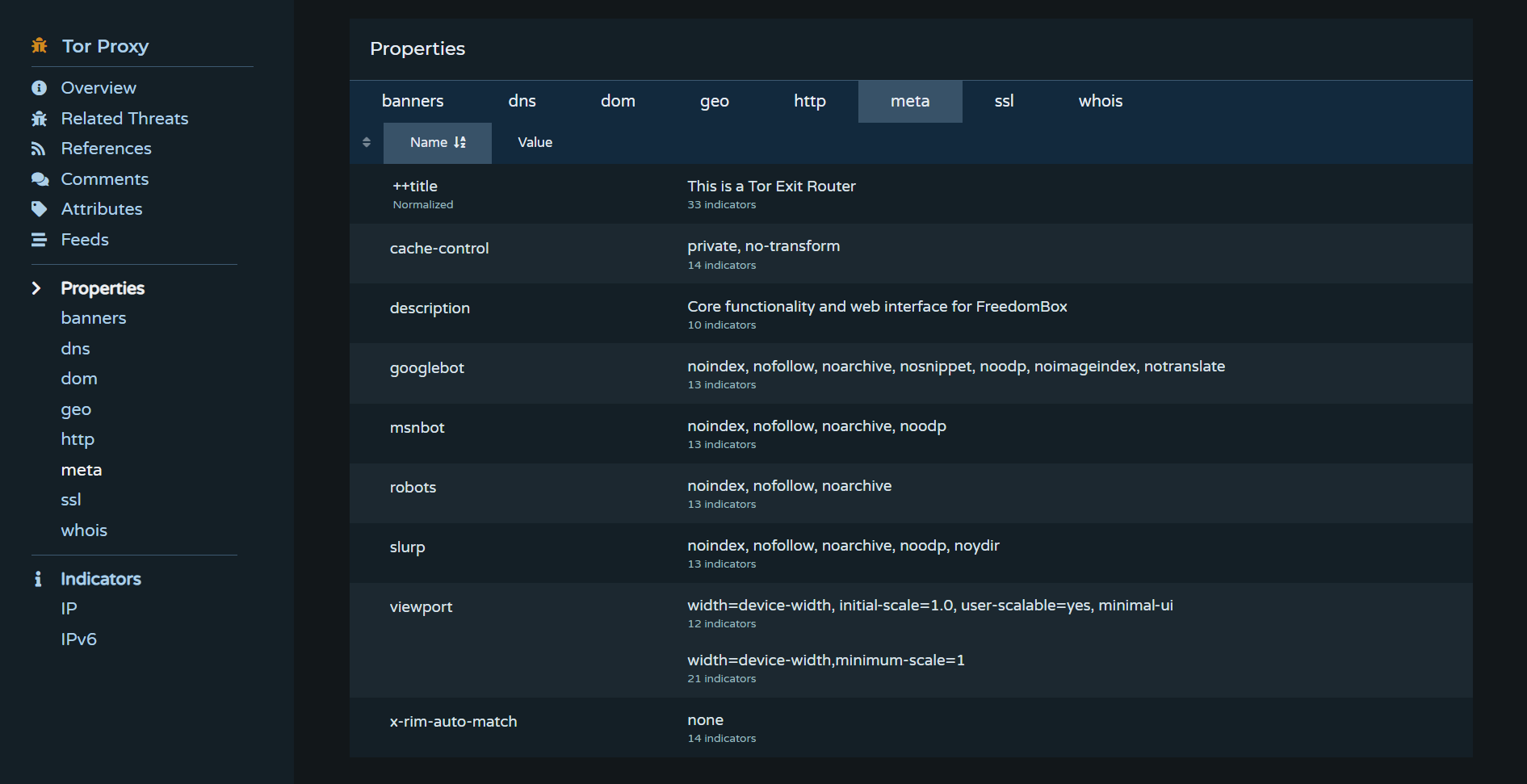
Faster Onboarding of New Data Types
When adding new data types, there's not much we need to update internally. All we need to do is create a new property type when passing new data from a collection source to Pulsedive's ingestion engine. This means we can deliver new data types for users as soon as we start collecting them, with minimal disruption.
Drawback: Reconstructing Historical Records
The biggest drawback of this approach is that it's difficult to reconstruct full historical records, such as a full WHOIS response from a previous request. Reconstructing the latest response is easy, of course, but timestamps for each property are limited. When a new WHOIS request is made, the timestamps for existing identical properties are updated to reflect that they are present in the latest request.
Storing timestamps for each property for each request made is too burdensome for several reasons (maintenance, indexing, querying, limited development resources, etc), so we cannot identify whether a specific property was present at a certain point in the past if it's been updated with a new request.
A worthwhile tradeoff: Since the main goal of providing this data is to provide analysts with context when determining if a host is malicious, we believe the latest data is the most important. While risk evaluations for a host seen in the past are important for alerting on historical log data in a SOC, our risk scoring methodology is to provide a long-term score.
For example, if an IP is rated malicious at one point in time by a third-party threat feed, analysts might choose to alert on it, but if it's a shared hosting IP or it rotates to another host, it will result in false positive alerts. It is much safer to alert on domains or URLs; that's why we are more conservative when rating IPs, and less so with URLs. And when determining the risk score, the latest data seen is often the most important to get a contemporary snapshot.
The advantages of our approach far outweigh the drawbacks, as we can provide higher-quality insights and more precise querying.
Conclusion
Pulsedive properties deliver value to analysts by providing quality insights and precise querying across indicator data. They enable us to continue improving our offerings with seamless onboarding of new data collection sources and minimal interruption after risk scoring enhancements. They help keep us lean and affordable by enabling efficient storage and fast response times.
As our capabilities grow, you can expect more data to be collected and parsed in new and exciting ways for more valuable and accurate insights.
